Avant de chercher à être visible, encore faut-il savoir ce que l’on mesure
Pendant près de trente ans, les entreprises ont appris à piloter leur visibilité sur Internet à l’aide d’indicateurs relativement simples. Une page occupait une première position dans Google ou n’y figurait pas. Une annonce publicitaire générait un certain nombre de clics. Un formulaire de contact était envoyé ou ne l’était pas. Même si ces indicateurs n’ont jamais été parfaits, ils avaient un mérite essentiel : ils reposaient sur des faits observables.
Cette distinction est fondamentale.
Une impression est un événement qui s’est produit. Un clic est une action réalisée par un internaute. Une visite est enregistrée par un serveur. Une conversion correspond à une action mesurable. Autrement dit, derrière chacun de ces indicateurs se cache un phénomène qui existe réellement et qui peut être observé, enregistré, comparé et analysé.
L’arrivée des intelligences artificielles génératives vient bouleverser cette logique.
Pour la première fois dans l’histoire du Web, une partie croissante des internautes ne consulte plus directement les pages qui contiennent l’information. Ils interrogent un intermédiaire – ChatGPT, Gemini, Claude, Perplexity ou un autre modèle de langage – qui se charge de produire une réponse synthétique en s’appuyant sur des connaissances préexistantes, des recherches en temps réel ou une combinaison des deux.
Cette évolution est loin d’être anecdotique.
Elle remet en question l’un des principes fondateurs du référencement naturel : celui selon lequel la visibilité d’une entreprise dépend principalement de sa capacité à apparaître dans les premiers résultats d’un moteur de recherche.
Aujourd’hui, une entreprise peut être recommandée sans que l’utilisateur ne consulte jamais Google. À l’inverse, elle peut bénéficier d’un excellent référencement naturel tout en étant totalement absente des réponses générées par les principales IA.
Une nouvelle problématique apparaît donc.

Comment mesurer sa visibilité lorsqu’elle dépend désormais d’un système conversationnel plutôt que d’une page de résultats ?
À première vue, la réponse semble évidente. Il suffirait d’interroger les différentes IA, de regarder quelles entreprises sont citées, puis de construire des indicateurs comparatifs.
C’est précisément ce que proposent aujourd’hui de nombreux outils présentés sous les appellations GEO (Generative Engine Optimization), LLMO (Large Language Model Optimization) ou encore AI Visibility Platforms. Les tableaux de bord se multiplient. Les graphiques donnent une impression de précision. Les pourcentages semblent traduire objectivement la visibilité d’une marque dans les réponses générées par les IA.
Pourtant, derrière cette apparente simplicité se cache une question beaucoup plus profonde.
Que mesure réellement un tel indicateur ?
Mesure-t-il un phénomène observable, comparable à un clic ou à une visite ? Ou s’agit-il d’une estimation construite à partir d’un modèle statistique dont les hypothèses sont rarement expliquées ?
Cette interrogation peut sembler théorique. Elle ne l’est pas.
Elle détermine directement la confiance que l’on peut accorder aux décisions prises à partir de ces chiffres.
Imaginons qu’un tableau de bord annonce qu’une entreprise dispose d’une visibilité de 42 % dans ChatGPT. Que signifie réellement ce nombre ? Correspond-il à 42 % des utilisateurs qui voient cette entreprise ? À 42 % des réponses produites par le modèle ? À 42 % des requêtes testées par l’éditeur de l’outil ? Ou à une estimation calculée à partir d’un échantillon de questions générées automatiquement ?
Sans connaître précisément ce qui est mesuré, le chiffre perd une grande partie de sa valeur.
Cette réflexion dépasse largement le seul domaine des intelligences artificielles.
Elle touche à une discipline beaucoup plus ancienne : la science de la mesure.
Depuis des siècles, scientifiques, ingénieurs et chercheurs savent qu’avant d’interpréter un résultat, il est indispensable de comprendre comment il a été obtenu. Un instrument de mesure possède toujours des limites, une précision, une incertitude et un domaine de validité. Un thermomètre ne mesure pas la même chose qu’une caméra thermique. Une balance de laboratoire n’offre pas la même précision qu’un pèse-personne. Dans tous les cas, la qualité de la décision dépend directement de la qualité de la mesure.
Le marketing digital n’échappe pas à cette règle, même si nous avons parfois tendance à l’oublier.
Les tableaux de bord modernes affichent des dizaines d’indicateurs avec plusieurs décimales, des graphiques élégants et des courbes parfaitement lissées. Cette sophistication visuelle donne souvent une illusion de précision. Pourtant, un indicateur présenté avec trois chiffres après la virgule n’est pas nécessairement plus fiable qu’un simple ordre de grandeur.
Les professionnels de la donnée connaissent bien ce phénomène. Plus un chiffre paraît précis, plus nous avons naturellement tendance à lui faire confiance. C’est un biais cognitif classique. Nous confondons facilement précision d’affichage et précision de la mesure.
Or ces deux notions sont très différentes.
L’émergence des IA génératives accentue encore cette confusion. Les nouveaux outils du marché produisent des scores, des indices de visibilité, des estimations de trafic ou des parts de voix qui donnent le sentiment de mesurer un phénomène parfaitement maîtrisé. Pourtant, la réalité est bien plus complexe.
Contrairement aux moteurs de recherche traditionnels, un modèle de langage ne renvoie pas toujours la même réponse à une question identique. Les données utilisées évoluent, les modèles sont régulièrement mis à jour, les mécanismes internes restent largement opaques et les fournisseurs modifient continuellement leurs systèmes sans en détailler le fonctionnement.
Autrement dit, nous cherchons à mesurer un objet qui évolue en permanence.
Cette particularité change profondément la nature même des indicateurs que nous pouvons produire.
C’est probablement le point le plus important de tout cet article.
La question n’est pas de savoir si les outils GEO sont « bons » ou « mauvais ». Elle n’est pas non plus de déterminer si le Query Fan-out constitue une bonne ou une mauvaise méthode. Ces débats sont souvent caricaturaux et passent à côté de l’essentiel.
La véritable question est beaucoup plus simple.
Sommes-nous en train d’observer un phénomène réel ou de construire une estimation plausible ?
La nuance est capitale.
Une observation correspond à un événement qui s’est effectivement produit. Une visite enregistrée dans les journaux d’un serveur en est un bon exemple. Le serveur ne formule aucune hypothèse ; il enregistre simplement une requête reçue à un instant donné.
Une estimation procède différemment. Elle cherche à approcher une réalité qui ne peut pas être observée directement. Pour cela, elle s’appuie sur un ensemble d’hypothèses, de modèles statistiques, d’extrapolations ou d’échantillons. Une estimation peut être extrêmement pertinente. Elle peut également être très éloignée de la réalité. Tout dépend de la qualité des hypothèses retenues.
Comprendre cette différence est indispensable pour analyser sereinement les nouveaux indicateurs proposés autour des intelligences artificielles.
Chez ONI, nous ne considérons pas que ces outils sont inutiles. Bien au contraire. Ils apportent des informations parfois très intéressantes et ouvrent de nouvelles perspectives d’analyse.
En revanche, nous pensons qu’il est essentiel de distinguer clairement trois niveaux de confiance dans une donnée.
Le premier est celui de l’observation. Il repose sur un événement directement mesuré.
Le second est celui de l’estimation. Il cherche à approcher une réalité à partir d’un modèle.
Le troisième est celui de l’extrapolation. Il consiste à déduire un phénomène plus large à partir d’un nombre limité d’observations.
Ces trois approches sont utiles. Mais elles ne répondent pas aux mêmes questions et ne doivent pas être interprétées avec le même niveau de certitude.
C’est précisément cette distinction que nous allons explorer dans les chapitres suivants.
Car avant de chercher à améliorer sa visibilité auprès des intelligences artificielles, il faut d’abord comprendre ce que l’on est réellement capable de mesurer… et accepter, avec une certaine humilité, que certaines réponses restent aujourd’hui des estimations plutôt que des certitudes.
Qu’est-ce qu’une mesure fiable ? Les enseignements de la métrologie
Si l’on demande à un dirigeant d’entreprise si la température extérieure est de 18,2 °C ou de 18,7 °C, il répondra probablement que cette différence n’a que peu d’importance. En revanche, si l’on demande à un ingénieur chargé de fabriquer une pièce d’avion si un diamètre mesure 10,00 mm ou 10,05 mm, la réponse sera tout autre. Dans certains domaines, quelques centièmes de millimètre suffisent à compromettre le fonctionnement d’un mécanisme entier.
Ces deux exemples illustrent une réalité simple : une mesure n’a de valeur que si l’on connaît la qualité de l’instrument qui l’a produite.
Cette idée paraît évidente lorsqu’il s’agit d’un thermomètre, d’une balance ou d’un pied à coulisse. Pourtant, elle disparaît presque totalement dès que l’on parle de données numériques. Devant un tableau de bord affichant des graphiques sophistiqués et des indicateurs calculés avec plusieurs décimales, nous avons spontanément tendance à considérer ces chiffres comme des faits. Nous oublions que, derrière chacun d’eux, se cache une méthode de calcul, un protocole de collecte et un certain nombre d’hypothèses.
Cette confusion n’est pas propre au marketing digital. Elle est suffisamment ancienne pour avoir donné naissance à une discipline scientifique à part entière : la métrologie, c’est-à-dire la science de la mesure.
La métrologie ne cherche pas uniquement à répondre à la question « combien ? ». Elle cherche d’abord à répondre à une question beaucoup plus fondamentale : peut-on faire confiance à cette mesure ?
Pour y répondre, plusieurs notions sont utilisées.
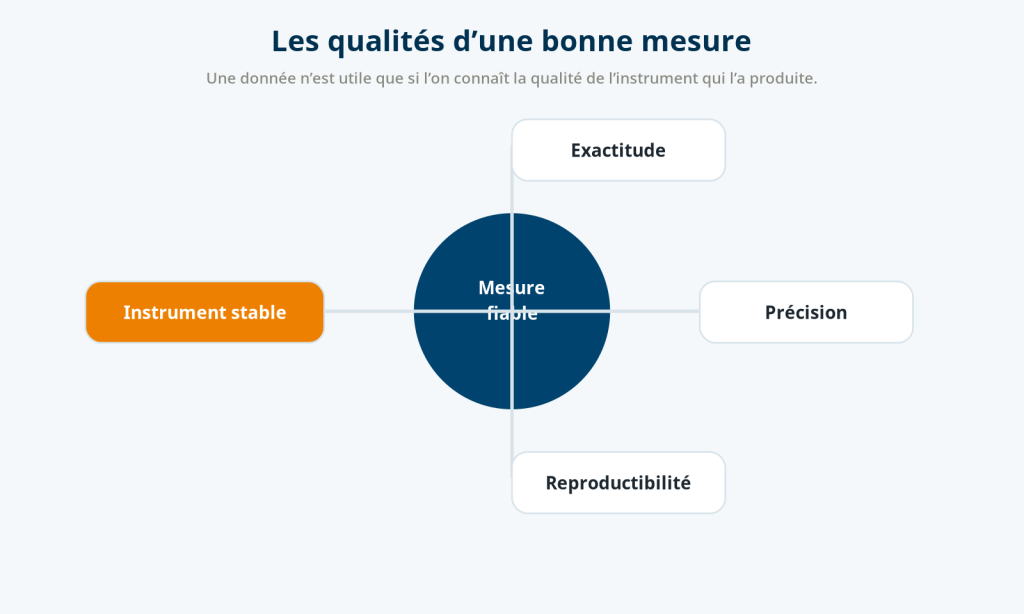
La première est l’exactitude. Une mesure est exacte lorsqu’elle est proche de la valeur réelle. La seconde est la précision. Elle correspond à la capacité d’un instrument à reproduire plusieurs fois la même mesure dans les mêmes conditions. Ces deux notions sont souvent confondues alors qu’elles décrivent des réalités très différentes (ISO 5725 – Accuracy (trueness and precision) of measurement methods).
Imaginons un archer qui tire dix flèches sur une cible.
Si toutes ses flèches arrivent très près les unes des autres mais loin du centre, son tir est précis mais inexact. Son geste est reproductible, mais il est mal réglé.
À l’inverse, si les flèches sont dispersées tout autour du centre, leur moyenne pourra sembler correcte, mais aucune mesure individuelle ne sera réellement fiable.
Enfin, dans le meilleur des cas, les flèches sont à la fois regroupées et proches du centre. La mesure est alors précise et exacte.
Cette distinction est fondamentale lorsque l’on commence à s’intéresser aux indicateurs produits par les intelligences artificielles.
Lorsqu’un outil annonce qu’une marque possède un « score de visibilité IA de 63 % », la première question ne devrait pas être : « Est-ce un bon score ? »
La première question devrait être : « Ce score est-il reproductible ? »
Si le même protocole appliqué quelques minutes plus tard conduit à un résultat sensiblement différent, nous ne sommes plus face à une mesure stable mais face à un indicateur dont l’incertitude devient elle-même un élément à prendre en compte.
La reproductibilité constitue d’ailleurs l’un des fondements de la méthode scientifique (The Logic of Scientific Discovery (1959) – Karl Popper). Une expérience n’est considérée comme solide que si d’autres chercheurs peuvent la reproduire dans des conditions comparables et obtenir des résultats similaires. Cette exigence permet de distinguer une observation robuste d’une simple coïncidence.
Or c’est précisément sur ce point que les modèles de langage introduisent une rupture majeure.
Contrairement à un thermomètre ou à une balance, un LLM n’est pas conçu pour fournir systématiquement la même réponse à une même question. Son objectif est de produire une réponse pertinente, naturelle et contextualisée, pas de constituer un instrument de mesure. Autrement dit, nous utilisons aujourd’hui comme instrument d’observation un système qui n’a jamais été conçu pour remplir cette fonction.
Cette remarque peut sembler anecdotique. Elle ne l’est pas.
Elle signifie que nous devons changer notre manière d’interpréter les résultats produits par les outils de GEO.
Une autre notion importante de la métrologie est celle des erreurs de mesure.
On distingue généralement deux grandes familles.
La première correspond aux erreurs aléatoires. Elles proviennent de petites variations imprévisibles. Elles peuvent souvent être réduites en multipliant les observations. C’est précisément ce principe qui justifie le recours aux méthodes statistiques : lorsqu’un phénomène est soumis à un bruit aléatoire, augmenter le nombre de mesures permet généralement de faire apparaître une tendance plus stable.
La seconde famille est beaucoup plus problématique. Il s’agit des erreurs systématiques, que l’on appelle également des biais. Contrairement aux erreurs aléatoires, elles ne disparaissent pas lorsque l’on augmente le nombre d’observations. Si une balance affiche systématiquement deux kilogrammes de trop, la peser cent fois ne corrigera jamais cette erreur. On obtiendra simplement cent fois la même mesure fausse.
Cette distinction est capitale pour comprendre les limites des méthodes actuelles de mesure de la visibilité des IA.
Le Query Fan-out, que nous détaillerons plus loin, repose précisément sur l’idée qu’en multipliant le nombre de requêtes adressées à un modèle de langage, il devient possible de lisser les fluctuations observées et de dégager une tendance statistique.
Cette approche est parfaitement cohérente… à condition que les variations observées soient essentiellement aléatoires.
Mais que se passe-t-il si le modèle lui-même évolue entre deux campagnes de mesure ? Que se passe-t-il si OpenAI, Google ou Anthropic modifient discrètement leur système de classement, leur moteur de recherche, leurs sources documentaires ou leur « system prompt » ? Dans ce cas, nous ne sommes plus confrontés à un simple bruit statistique. Nous sommes face à un changement de l’instrument lui-même.
C’est ici que se situe probablement la principale difficulté des mesures appliquées aux intelligences artificielles.
Dans la plupart des disciplines scientifiques, l’instrument de mesure est supposé stable pendant toute la durée de l’expérience. Avec les LLM, cette hypothèse n’est plus garantie.
Cette situation conduit à une question rarement posée mais pourtant essentielle.
Peut-on comparer deux mesures obtenues avec un instrument qui n’est plus exactement le même ?
À première vue, la réponse semble évidente : bien sûr que non.
Pourtant, c’est exactement ce que proposent aujourd’hui la plupart des tableaux de bord consacrés à la visibilité des IA. Ils affichent des courbes mensuelles, des évolutions trimestrielles ou des progressions annuelles comme si l’objet mesuré était resté parfaitement identique au fil du temps.
Cette représentation est séduisante. Elle facilite la lecture. Elle rassure les utilisateurs.
Mais elle masque une réalité beaucoup plus complexe : une partie des variations observées peut provenir non pas de l’évolution de votre visibilité, mais de l’évolution du modèle chargé de la mesurer.
Cette simple constatation ne suffit pas à invalider les méthodes actuelles. En revanche, elle oblige à les interpréter avec beaucoup plus de prudence.
Avant même d’étudier les différentes techniques de mesure de la visibilité des IA, une première conclusion peut donc être formulée.
Toutes les données ne possèdent pas le même niveau de confiance.
Certaines correspondent à des observations directes. D’autres sont des estimations. D’autres enfin résultent d’extrapolations plus ou moins ambitieuses. Comprendre cette hiérarchie constitue probablement la première compétence que devront acquérir les entreprises pour piloter efficacement leur visibilité dans un monde où les intelligences artificielles jouent un rôle croissant dans l’accès à l’information.
Pourquoi les modèles de langage sont des objets particulièrement difficiles à mesurer
Les deux premières parties de cet article avaient un objectif précis : rappeler qu’avant d’interpréter une mesure, il est indispensable de comprendre la nature de l’instrument qui l’a produite. Cette précaution peut sembler évidente lorsqu’il s’agit d’une balance, d’un thermomètre ou d’un appareil de laboratoire. Elle l’est beaucoup moins dans l’univers du numérique, où les indicateurs sont souvent présentés avec une telle précision qu’ils donnent spontanément une impression de vérité.
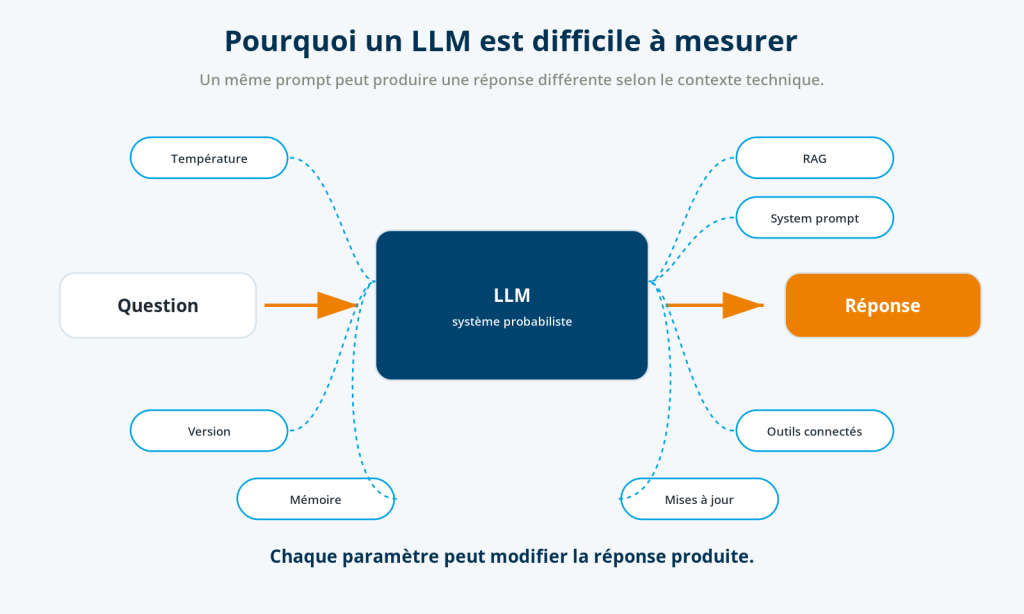
Or les intelligences artificielles génératives introduisent une difficulté supplémentaire. Elles ne constituent pas uniquement un nouvel outil d’accès à l’information ; elles changent profondément la nature de l’objet que nous cherchons à mesurer.
Pendant plus de vingt ans, les spécialistes du référencement naturel ont travaillé sur un système relativement déterministe : le moteur de recherche. Bien entendu, Google a toujours été complexe. Son algorithme a évolué des milliers de fois et les résultats ont toujours varié selon la localisation, la personnalisation ou le contexte de recherche. Mais, malgré cette complexité, un principe demeurait : à un instant donné, une requête donnée produisait une page de résultats relativement stable. Deux personnes relativement semblables effectuant la même recherche obtenaient généralement un classement comparable. Cette stabilité rendait possible l’observation, la comparaison et le suivi dans le temps.
Les modèles de langage fonctionnent selon une logique totalement différente.
Ils ne cherchent pas à retrouver une information préexistante dans un index documentaire. Leur objectif est de produire une réponse qui paraisse cohérente, pertinente et naturelle au regard de la question posée. Cette différence peut sembler subtile ; elle est pourtant fondamentale. Dans un moteur de recherche, le résultat existe déjà. Dans un LLM, la réponse est générée au moment où la question est posée.
Cette simple distinction explique une grande partie des difficultés rencontrées aujourd’hui par les professionnels du GEO.
Les LLM ne sont pas des bases de données
L’une des erreurs les plus fréquentes consiste à imaginer qu’un modèle de langage fonctionne comme une immense encyclopédie dans laquelle il suffirait de rechercher une information.
Cette représentation est rassurante, mais elle est inexacte.
Un LLM ne possède pas une fiche intitulée « meilleures agences SEO françaises » dans laquelle seraient stockés des noms d’entreprises classés par ordre de qualité. Il ne consulte pas davantage une base de données contenant des millions de réponses prédéfinies.
Le modèle calcule, mot après mot, la suite la plus probable à produire compte tenu du contexte dont il dispose. Cette nuance est essentielle. Lorsqu’il cite une entreprise, il ne la « retrouve » pas comme le ferait un moteur de recherche. Il estime qu’à cet instant précis, dans ce contexte particulier, cette référence contribue à produire une réponse jugée pertinente.
Autrement dit, la citation d’une marque n’est pas un objet fixe. C’est le résultat d’un calcul probabiliste (Brown et al. Language Models are Few-Shot Learners).
Cette caractéristique rend déjà toute tentative de mesure beaucoup plus délicate que dans le référencement naturel traditionnel.
Une même question ne produit pas toujours la même réponse
Cette dimension probabiliste est souvent mal comprise.
Lorsqu’un internaute interroge un moteur de recherche, il s’attend à retrouver sensiblement les mêmes résultats d’une recherche à l’autre. Les différences existent, mais elles restent généralement limitées.
Avec un modèle de langage, cette attente n’est plus toujours vérifiée.
La même question peut produire des formulations différentes, des exemples différents, parfois même des références différentes. Cette variabilité n’est pas un dysfonctionnement ; elle fait partie intégrante du fonctionnement des LLM. Elle permet d’éviter des réponses répétitives et favorise des échanges plus naturels.
Pour un utilisateur, cette souplesse constitue un avantage.
Pour celui qui cherche à mesurer la visibilité d’une entreprise, elle devient une difficulté méthodologique majeure.
Comment comparer deux réponses si le système n’a jamais eu pour objectif de produire exactement la même ?
Cette question peut paraître théorique. Elle est pourtant au cœur de toutes les méthodes actuelles de mesure de la visibilité des intelligences artificielles.
Les modèles évoluent en permanence
À cette première difficulté s’en ajoute une seconde, souvent sous-estimée.
Un moteur de recherche annonce généralement ses grandes mises à jour. Les spécialistes du référencement peuvent identifier une évolution importante, analyser ses conséquences et replacer leurs observations dans un contexte précis.
Les fournisseurs de modèles de langage fonctionnent différemment.
OpenAI, Google, Anthropic ou Perplexity améliorent continuellement leurs modèles. Certaines évolutions sont annoncées publiquement (voir les OpenAI System Card). Beaucoup d’autres ne le sont pas. Une modification du système de recherche intégré, un changement dans les sources documentaires, une évolution du system prompt ou une nouvelle stratégie de génération peuvent modifier les réponses sans que l’utilisateur en soit informé.
En pratique, cela signifie qu’une campagne de mesure réalisée aujourd’hui n’est pas forcément comparable à une campagne identique réalisée dans trois mois.
Le phénomène observé a peut-être changé.
Mais l’instrument chargé de l’observer aussi.
Cette distinction est essentielle, car elle remet en question l’interprétation de nombreuses courbes d’évolution proposées par certains outils du marché.
Un système dont nous ne maîtrisons pratiquement aucun paramètre
Une autre différence fondamentale mérite d’être soulignée.
Lorsque nous analysons un serveur web, un CRM ou une campagne Google Ads, nous connaissons généralement les paramètres qui influencent les résultats. Nous pouvons documenter le contexte de l’expérience et reproduire les mêmes conditions quelques jours plus tard.
Avec les grands modèles de langage, cette maîtrise disparaît presque totalement.
L’utilisateur ignore généralement :
- la version exacte du modèle utilisée ;
- les instructions système qui orientent ses réponses ;
- les sources éventuellement consultées en temps réel ;
- les mécanismes de pondération appliqués aux différentes références ;
- les critères utilisés pour sélectionner une entreprise plutôt qu’une autre.
Autrement dit, nous cherchons à mesurer un phénomène dont une grande partie des variables reste inaccessible.
En science expérimentale, une telle situation conduirait naturellement à beaucoup de prudence dans l’interprétation des résultats.
Il est donc surprenant de constater qu’à l’inverse, certains tableaux de bord présentent aujourd’hui leurs indicateurs avec une précision qui laisse penser que toutes ces variables seraient parfaitement maîtrisées.
Les conséquences pour les entreprises
Faut-il en conclure qu’il est impossible de mesurer sa visibilité sur les intelligences artificielles ?
Certainement pas.
En revanche, il faut accepter que les méthodes employées ne puissent pas offrir le même niveau de certitude que celles utilisées jusqu’à présent pour analyser le référencement naturel.
Cette différence est fondamentale.
Pendant des années, les professionnels du SEO ont travaillé avec des systèmes essentiellement déterministes. Ils disposaient de positions, de clics, d’impressions, de journaux de serveurs et d’indicateurs relativement stables.
Aujourd’hui, ils tentent d’appliquer ces mêmes réflexes à des systèmes probabilistes dont les règles de fonctionnement évoluent en permanence.
Cette transposition explique probablement une grande partie des incompréhensions qui entourent actuellement le GEO.
Les attentes sont celles du référencement classique.
L’objet étudié, lui, appartient déjà à une autre catégorie.
Comprendre cette différence constitue une étape indispensable avant d’examiner les méthodes qui ont été développées pour contourner ces difficultés.
La plus connue d’entre elles porte un nom que l’on retrouve désormais dans la plupart des outils spécialisés : le Query Fan-out. Son principe est particulièrement ingénieux. Mais, comme nous allons le voir, son interprétation mérite elle aussi d’être examinée avec beaucoup de rigueur.
Les méthodes actuelles de mesure : entre observation, expérimentation, estimation et extrapolation
À ce stade de notre réflexion, une première conclusion s’impose.
Il serait erroné d’opposer les différentes méthodes utilisées aujourd’hui pour évaluer la visibilité d’une entreprise auprès des intelligences artificielles. Chacune répond à une problématique différente et possède son propre domaine de validité. Le véritable risque ne réside pas dans les méthodes elles-mêmes, mais dans l’interprétation que l’on fait des résultats qu’elles produisent.
Depuis quelques mois, un vocabulaire nouveau s’est imposé dans l’univers du marketing digital. Les expressions AI Visibility, Share of Voice IA, LLM Visibility ou encore GEO Score se multiplient dans les présentations commerciales des éditeurs d’outils. Derrière ces termes se cachent pourtant des réalités très différentes, souvent présentées comme si elles étaient comparables.
Or elles ne le sont pas.
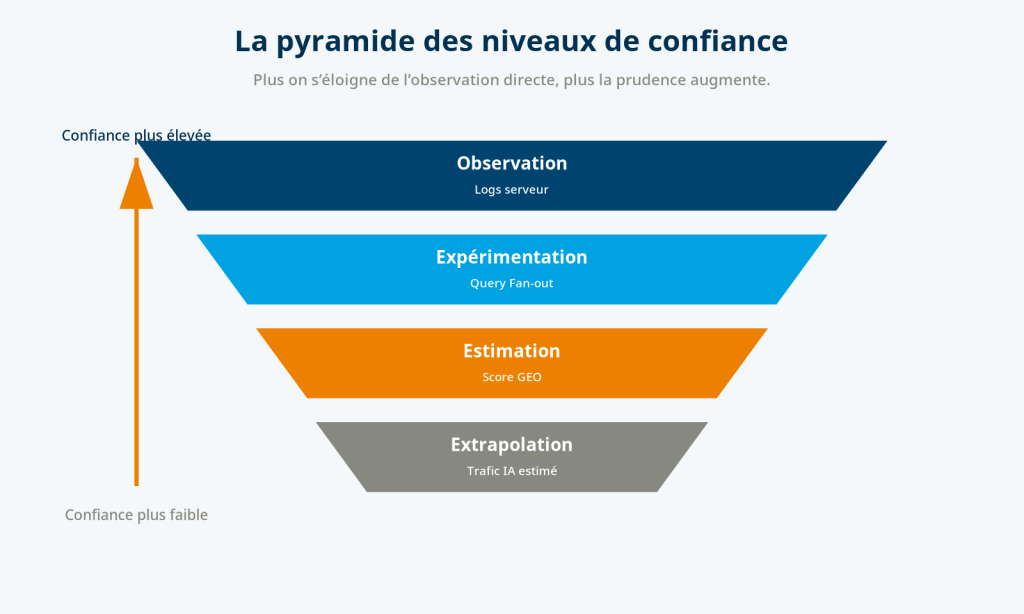
Avant même de s’intéresser aux technologies employées, il convient de distinguer quatre niveaux de connaissance qui sont fréquemment confondus : l’observation, l’expérimentation, l’estimation et l’extrapolation.
Cette distinction constitue probablement l’un des points les plus importants de cet article.
Une confusion largement entretenue par le marché
Les professionnels du marketing aiment les indicateurs simples :
- Un taux de conversion.
- Un coût d’acquisition.
- Une position moyenne.
- Une part de marché.
Ces indicateurs ont un avantage considérable : ils permettent de résumer une réalité complexe sous la forme d’un chiffre facilement comparable dans le temps.
L’industrie du GEO suit aujourd’hui exactement la même logique.
Les tableaux de bord affichent des scores de visibilité, des indices de présence ou des estimations de trafic qui donnent immédiatement le sentiment que le phénomène est parfaitement maîtrisé. Plus le graphique est élégant, plus le chiffre est précis, plus l’utilisateur a naturellement tendance à lui accorder de la crédibilité.
Pourtant, cette présentation masque souvent une réalité beaucoup plus nuancée.
Deux indicateurs affichés avec la même précision peuvent reposer sur des niveaux de confiance radicalement différents.
Comparer un nombre de visites réellement enregistrées dans les journaux d’un serveur avec un score calculé à partir de plusieurs milliers de simulations revient à comparer deux objets de nature différente.
Le premier correspond à un fait.
Le second correspond à une interprétation.
La différence est loin d’être anodine.
L’observation : constater un phénomène réel
Le premier niveau est celui de l’observation.
Une observation ne cherche pas à interpréter la réalité. Elle constate simplement qu’un événement s’est produit.
Lorsqu’un serveur enregistre une requête HTTP, il ne formule aucune hypothèse sur les raisons de cette visite. Il indique simplement qu’à une date, une heure et selon un protocole précis, un client a demandé le chargement d’une ressource.
De la même manière, lorsqu’un logiciel d’analyse enregistre une conversion, un téléchargement ou l’envoi d’un formulaire, il s’appuie sur un événement observable.
Bien entendu, même ces données peuvent comporter des limites. Certains bloqueurs de publicité empêchent le déclenchement de certains outils statistiques. Des applications mobiles ne transmettent pas toujours toutes les informations de provenance. Les robots peuvent parfois être confondus avec des visiteurs humains.
Mais malgré ces imperfections, nous restons dans le domaine de l’observation.
Un phénomène s’est effectivement produit.
Nous ne faisons qu’en prendre connaissance.
Cette nuance est fondamentale, car elle constitue le niveau de confiance le plus élevé dont nous disposions aujourd’hui dans l’univers numérique.
Le Query Fan-out : une expérimentation, pas une mesure
Le deuxième niveau est celui de l’expérimentation.
C’est précisément dans cette catégorie que nous proposons de classer le Query Fan-out.
Le principe est désormais bien connu.
Au lieu d’interroger une intelligence artificielle avec une seule requête, un système génère plusieurs dizaines, plusieurs centaines, voire plusieurs milliers de formulations différentes autour d’un même sujet. Les réponses sont ensuite analysées afin d’identifier les marques citées, leur fréquence d’apparition ou encore leur position dans le discours produit par le modèle.
Cette méthode est ingénieuse.
Elle répond à une difficulté que nous avons évoquée précédemment : un modèle de langage ne produit pas toujours exactement la même réponse. Multiplier les observations permet donc de réduire une partie de la variabilité liée au caractère probabiliste du système.
Cependant, qualifier cette approche de « mesure de visibilité » nous paraît scientifiquement discutable.
Pourquoi ?
Parce que le Query Fan-out ne mesure pas directement une grandeur observable.
Il construit un protocole expérimental destiné à observer le comportement d’un modèle de langage dans des conditions données.
La différence peut sembler subtile.
Elle est pourtant essentielle.
Prenons un exemple.
Imaginons qu’un psychologue souhaite étudier la réaction d’un groupe d’individus face à une même situation. Il soumet plusieurs centaines de personnes au même test, recueille leurs réponses, puis établit des statistiques.
Personne n’affirmera qu’il a « mesuré » l’intelligence humaine.
Il a observé un comportement dans un protocole expérimental.
Le Query Fan-out fonctionne selon une logique comparable.
Il ne mesure pas la visibilité réelle d’une entreprise auprès des utilisateurs.
Il observe la manière dont un modèle répond à une série de sollicitations soigneusement préparées.
Cette distinction change profondément la manière dont les résultats doivent être interprétés.
L’estimation : construire un modèle de la réalité
Le troisième niveau correspond à l’estimation.
Lorsqu’un outil annonce :
« Votre visibilité IA est de 58 %. »
ou
« Votre marque possède une part de voix de 34 %. »
il ne s’appuie généralement pas sur une observation directe.
Le chiffre résulte d’un modèle.
Autrement dit, plusieurs observations expérimentales sont combinées, pondérées, corrigées et transformées en un indicateur synthétique destiné à représenter une réalité beaucoup plus complexe.
Cette démarche est parfaitement légitime. Les statisticiens procèdent ainsi depuis des décennies. Les instituts de sondage estiment les intentions de vote. Les économistes estiment la croissance. Les météorologues estiment la trajectoire d’un cyclone. Dans tous ces cas, personne ne prétend mesurer directement le phénomène.
On construit un modèle dont l’objectif est de s’en approcher.
Le problème n’est donc pas l’existence de ces estimations.
Le problème apparaît lorsque leur nature est oubliée.
Une estimation n’est jamais une observation. Elle dépend toujours des hypothèses retenues lors de sa construction.
Changer les hypothèses revient souvent à modifier le résultat.
L’extrapolation : lorsque le modèle devient une prédiction
Le dernier niveau est celui de l’extrapolation.
Il consiste à utiliser une estimation afin de produire un indicateur qui n’a jamais été observé.
Prenons un exemple volontairement simplifié.
Un outil constate qu’une entreprise apparaît dans 60 % des réponses générées lors d’un Query Fan-out.
Il combine ensuite cette information avec un volume supposé d’utilisateurs de ChatGPT, applique un taux de clic estimé, puis conclut : « Votre site reçoit probablement 2 300 visites mensuelles depuis les IA. »
Cette valeur peut être pertinente. Elle peut également être très éloignée de la réalité. Personne ne le sait. Car cette donnée n’a jamais été observée.
Elle résulte d’une succession de modèles statistiques dont chacun introduit sa propre marge d’incertitude.
Plus on s’éloigne de l’observation initiale, plus le niveau de confiance diminue.
Il ne s’agit pas d’une critique des outils du marché.
C’est simplement une conséquence logique de leur méthode de fonctionnement.
Ne disposant pas d’un accès direct aux données réelles des plateformes d’intelligence artificielle, ils sont contraints de reconstruire une image de la réalité à partir d’informations partielles.
Autrement dit, ils ne trichent pas.
Ils modélisent.
Tous les indicateurs ne possèdent pas le même niveau de confiance
Cette distinction entre observation, expérimentation, estimation et extrapolation nous paraît essentielle.
Elle ne cherche pas à établir une hiérarchie morale entre les méthodes.
Chaque niveau répond à un besoin particulier :
- L’observation permet de constater un fait.
- L’expérimentation permet d’étudier un comportement.
- L’estimation permet d’approcher une réalité difficilement observable.
- L’extrapolation permet d’imaginer un phénomène plus large à partir d’informations limitées.
Le problème apparaît uniquement lorsque ces quatre niveaux sont présentés comme s’ils possédaient la même valeur.
Or ce n’est pas le cas.
Un dirigeant qui pilote son entreprise a tout intérêt à savoir si le chiffre qu’il consulte provient d’un événement réellement observé, d’un protocole expérimental, d’un modèle statistique ou d’une extrapolation.
Cette simple information change complètement le niveau de confiance qu’il est raisonnable d’accorder à la donnée.
C’est probablement l’un des principaux enseignements de cet article.
Toutes les données n’ont pas le même niveau de confiance. Confondre une observation, une expérimentation, une estimation et une extrapolation constitue aujourd’hui l’une des principales sources de confusion autour de la visibilité des intelligences artificielles.
Cette distinction nous permet désormais d’aborder la dernière question essentielle : pourquoi les outils commerciaux produisent-ils des indicateurs qui semblent parfois si précis alors qu’ils n’ont, par définition, pas accès aux données internes de ChatGPT, Gemini ou Claude ? Pour répondre à cette interrogation, il faut comprendre comment ces plateformes reconstruisent la réalité à partir d’informations partielles, et pourquoi cette approche est à la fois indispensable… et intrinsèquement limitée.
Pourquoi les outils GEO produisent-ils des estimations ?
À ce stade de notre réflexion, une objection parfaitement légitime peut apparaître.
Si les modèles de langage sont aussi difficiles à mesurer, comment expliquer que des acteurs reconnus comme Semrush, Ahrefs, Similarweb ou d’autres plateformes spécialisées soient capables d’afficher des tableaux de bord détaillés, des courbes d’évolution, des parts de voix ou encore des estimations de trafic provenant des intelligences artificielles ?
La réponse est simple.
Ils ne disposent pas d’une information que personne, en dehors des éditeurs des modèles eux-mêmes, ne possède.
Pour comprendre cette situation, il faut revenir à une distinction essentielle entre les données de première main et les données reconstruites.
Les données que personne ne possède
Lorsqu’un internaute pose une question à ChatGPT, Gemini ou Claude, plusieurs informations sont générées.
Le modèle connaît naturellement la question posée.
Il connaît la réponse produite.
Il sait éventuellement quelles sources ont été consultées.
Il sait si l’utilisateur a cliqué sur un lien proposé.
Il connaît le contexte de la conversation.
Toutes ces informations appartiennent exclusivement à l’éditeur du modèle.
OpenAI ne les partage pas.
Anthropic ne les partage pas.
Google n’en diffuse qu’une partie très limitée.
Autrement dit, aucun outil de référencement ne peut savoir avec certitude combien de fois votre entreprise a réellement été recommandée par ChatGPT au cours de la journée, ni combien d’utilisateurs ont effectivement vu cette recommandation.
Cette donnée existe.
Mais elle n’est pas accessible.
Il s’agit probablement de la différence la plus importante entre le référencement traditionnel et l’univers des intelligences artificielles.
Pendant des années, Google a progressivement ouvert une partie de ses données grâce à Google Search Console. Les référenceurs pouvaient connaître les impressions, les clics, les positions moyennes ou encore les requêtes ayant déclenché l’affichage d’une page.
Rien d’équivalent n’existe aujourd’hui pour les grands modèles de langage.
Les outils spécialisés sont donc confrontés à une difficulté majeure : ils doivent décrire un phénomène auquel ils n’ont pas directement accès.
Lorsqu’on ne peut pas observer, il faut modéliser
Cette situation est loin d’être exceptionnelle. De nombreuses disciplines scientifiques fonctionnent exactement de la même manière.
Les météorologues ne mesurent pas directement le climat de demain. Ils construisent des modèles.
Les économistes n’observent pas immédiatement la croissance future. Ils élaborent des projections.
Les démographes estiment la population d’un pays entre deux recensements. Ils utilisent des modèles statistiques.
Les outils de GEO procèdent selon une logique comparable.
Ne pouvant accéder aux données réelles des plateformes d’IA, ils reconstruisent une représentation du phénomène à partir d’informations partielles.
Ils combinent différents types de données :
- des expérimentations, comme le Query Fan-out ;
- des observations publiques du Web ;
- des panels de navigation (clickstream) ;
- des modèles statistiques ;
- parfois des données issues de leurs propres bases historiques.
Aucune de ces sources n’est fausse.
Aucune n’est suffisante à elle seule.
C’est leur combinaison qui permet de produire une estimation.
Il serait donc injuste de reprocher à ces outils de ne pas fournir une mesure exacte.
Ils ne le peuvent tout simplement pas.

Le piège de la précision apparente
Là où la situation devient plus délicate, c’est dans la manière dont ces estimations sont présentées.
Prenons un exemple volontairement caricatural.
Supposons qu’un tableau de bord affiche :
Trafic IA estimé : 1 842 visites ce mois-ci.
Psychologiquement, ce chiffre produit un effet immédiat.
Il donne l’impression d’une mesure extrêmement précise.
Pourquoi 1 842 et non 1 800 ?
Pourquoi pas 1 750 ?
Cette précision apparente renforce naturellement la confiance de l’utilisateur.
Pourtant, rien ne permet d’affirmer que le trafic réel soit de 1 842 visites.
Il pourrait être de 1 200.
Ou de 2 300.
Le chiffre affiché constitue la sortie d’un modèle.
Pas le résultat d’un comptage.
Cette distinction est importante, car elle illustre un biais bien connu en métrologie comme en statistique.
Un calcul peut produire un résultat très précis.
Cela ne signifie pas que la réalité l’est tout autant.
Autrement dit, la précision d’un calcul ne garantit jamais l’exactitude de la mesure.
Une estimation peut être extrêmement utile
Faut-il pour autant écarter ces outils ?
Certainement pas.
Une estimation pertinente vaut souvent mieux que l’absence totale d’information.
Si un modèle est construit avec rigueur, il peut permettre :
- d’observer des tendances ;
- de comparer plusieurs stratégies ;
- de détecter des évolutions ;
- d’orienter des décisions.
Les économistes utilisent des estimations.
Les climatologues utilisent des estimations.
Les assureurs utilisent des estimations.
Le marketing n’échappe pas à cette règle.
Le véritable enjeu n’est donc pas de savoir si ces indicateurs sont utiles.
Il consiste à comprendre ce qu’ils représentent réellement.
Une estimation n’est pas une observation.
Une extrapolation n’est pas un comptage.
Confondre ces différents niveaux de confiance revient à attribuer aux modèles une précision qu’ils ne prétendent d’ailleurs pas toujours posséder.
Une question demeure
À ce stade, une interrogation subsiste pourtant.
Si aucun outil du marché ne peut observer directement la réalité, existe-t-il malgré tout une source de données plus proche des faits ?
Autrement dit, existe-t-il une manière d’observer non pas ce que les intelligences artificielles auraient pu recommander… mais ce qu’elles ont réellement envoyé vers votre site ?
La réponse est oui.
Elle ne se trouve ni dans les plateformes de GEO, ni dans les modèles statistiques.
Elle se trouve beaucoup plus près de votre site Internet : dans les journaux de votre propre serveur.
C’est précisément cette approche que nous avons choisi de privilégier chez ONI.
Pourquoi les données de première main valent davantage que les estimations
Depuis plusieurs chapitres, une idée revient régulièrement sans avoir encore été formulée explicitement.
Toutes les données ne possèdent pas le même niveau de confiance.
Certaines sont observées directement.
D’autres sont déduites.
D’autres encore sont calculées à partir de modèles statistiques parfois très sophistiqués.
Cette hiérarchie n’a rien de nouveau. Elle existe dans toutes les disciplines scientifiques. Lorsqu’un chercheur dispose d’une observation directe, il lui accordera toujours davantage de crédit qu’à une estimation construite à partir d’hypothèses, aussi pertinentes soient-elles.
Le marketing numérique devrait suivre exactement la même logique.
Pourtant, au fil des années, les entreprises ont progressivement pris l’habitude de piloter leur activité à partir d’indicateurs toujours plus nombreux, parfois sans s’interroger sur leur origine. Les tableaux de bord se sont enrichis de dizaines de graphiques, de scores propriétaires et d’indices calculés par des plateformes dont les méthodes restent souvent confidentielles.
Cette évolution présente un risque.
À force de consulter des indicateurs, nous oublions parfois de nous demander s’ils décrivent réellement un phénomène observé ou s’ils constituent simplement la meilleure approximation actuellement disponible.
Cette distinction est pourtant essentielle.
Prenons un exemple simple.
Une plateforme estime que votre entreprise reçoit environ deux mille visites mensuelles depuis les intelligences artificielles.
Votre serveur, lui, enregistre mille deux cents visites identifiées comme provenant directement de ces plateformes.
Lequel de ces deux chiffres faut-il privilégier ?
À première vue, la réponse paraît évidente.
Le second.
Non pas parce qu’il est nécessairement parfait, mais parce qu’il correspond à un événement qui s’est effectivement produit.
Le premier cherche à représenter la réalité.
Le second fait partie de cette réalité.
Cette différence est fondamentale.
Elle nous conduit à distinguer deux grandes familles de données.
Les données de première main sont produites directement par le système que l’on cherche à observer. Elles proviennent de vos propres outils, de vos propres serveurs, de vos propres applications. Elles peuvent naturellement contenir des imperfections, mais leur origine est parfaitement connue.
Les données de seconde main, à l’inverse, résultent d’un traitement réalisé par un tiers. Elles sont souvent enrichies, corrigées, agrégées ou modélisées avant d’être présentées sous la forme d’un indicateur.
Aucune de ces approches n’est mauvaise.
Elles répondent simplement à des objectifs différents.
Les données de seconde main permettent souvent d’obtenir une vision globale impossible à construire autrement. Elles sont indispensables pour comparer un marché, estimer une audience ou analyser un environnement concurrentiel.
Les données de première main répondent à une autre question.
Elles permettent de savoir ce qui s’est réellement passé sur votre propre infrastructure.
Dans le contexte des intelligences artificielles génératives, cette différence prend une importance particulière.
Aucun outil externe ne peut connaître avec certitude le nombre de fois où votre entreprise a été recommandée par ChatGPT. En revanche, votre propre serveur est capable d’enregistrer les visiteurs qui ont effectivement suivi un lien depuis ChatGPT vers votre site.
Il ne s’agit plus d’une estimation.
Il s’agit d’un événement.

Les journaux du serveur : une source de vérité souvent sous-estimée
Chaque fois qu’un navigateur, un robot ou une application demande l’affichage d’une page de votre site, votre serveur enregistre une série d’informations techniques.
La date et l’heure de la requête.
La ressource demandée.
L’adresse IP du client.
Le code de réponse renvoyé.
Le logiciel utilisé pour accéder au site, que l’on appelle généralement le User-Agent.
Selon les cas, l’origine de la visite (Referer) est également transmise.
Ces informations ne racontent pas toute l’histoire.
Elles ne permettent pas de savoir ce que l’utilisateur pensait, pourquoi il a cliqué ou ce qu’il fera ensuite.
En revanche, elles possèdent une qualité essentielle.
Elles décrivent un événement réel.
Lorsqu’un visiteur provenant de ChatGPT charge une page de votre site et que cette information est transmise, votre serveur ne formule aucune hypothèse.
Il constate simplement qu’une connexion a eu lieu.
C’est précisément cette philosophie que nous privilégions chez ONI.
Nous ne considérons pas les journaux de serveur comme une solution miracle.
Ils présentent eux aussi des limites.
Certaines applications mobiles ne transmettent pas systématiquement les informations de provenance.
Les robots évoluent.
Les User-Agent changent.
Les politiques de confidentialité se renforcent.
Mais malgré ces imperfections, les journaux de serveur restent aujourd’hui la source la plus proche de la réalité dont dispose une entreprise.
Ils permettent d’observer ce qui s’est effectivement produit, et non ce que l’on suppose avoir eu lieu.
Pourquoi nous avons développé nos propres outils
Cette conviction explique également une grande partie des choix technologiques réalisés chez ONI.
Au fil des années, nous avons progressivement réduit notre dépendance à de nombreux indicateurs propriétaires afin de développer des outils reposant autant que possible sur des données de première main.
Cette démarche ne traduit aucune défiance à l’égard des solutions du marché.
Nous continuons à utiliser de nombreux outils spécialisés lorsque leur valeur ajoutée est démontrée.
En revanche, lorsqu’une décision stratégique engage la visibilité ou le développement commercial d’une entreprise, nous estimons qu’il est préférable de partir des données les plus proches de la réalité observable.
C’est dans cet esprit que nous avons développé nos propres outils d’analyse du trafic provenant des intelligences artificielles.
Leur objectif n’est pas de concurrencer les plateformes de GEO.
Ils répondent à une question beaucoup plus simple.
Combien de visiteurs les intelligences artificielles ont-elles réellement envoyés vers votre site ?
Cette approche ne prétend pas tout mesurer.
Elle ne permet pas de connaître toutes les recommandations formulées par les modèles.
Elle ne remplace pas les analyses concurrentielles ni les expérimentations de type Query Fan-out.
En revanche, elle apporte un élément que les estimations ne peuvent offrir.
Elle repose sur des événements qui se sont effectivement produits.
Et lorsque l’on cherche à piloter une stratégie de visibilité, cette distinction mérite probablement davantage d’attention qu’elle n’en reçoit aujourd’hui.
Conclusion : mesurer moins… mais mesurer mieux
Si cet article devait être résumé en une seule phrase, ce serait probablement celle-ci :
Toutes les données ne se valent pas.
Cette affirmation peut sembler évidente. Pourtant, elle est régulièrement oubliée dès lors que les indicateurs deviennent suffisamment séduisants pour donner l’illusion de représenter fidèlement la réalité.
Depuis plusieurs années, le marketing digital s’est progressivement enrichi de dizaines de nouveaux KPI. Chaque innovation technologique s’accompagne de ses propres tableaux de bord, de ses nouveaux scores, de ses indices propriétaires et de ses métriques censées simplifier la prise de décision. L’émergence des intelligences artificielles génératives n’échappe pas à cette logique. À peine les premiers modèles conversationnels se sont-ils imposés auprès du grand public que de nouveaux outils promettaient déjà de mesurer la visibilité d’une entreprise dans ChatGPT, Gemini, Claude ou Perplexity.
Cette évolution est parfaitement compréhensible.
Une entreprise qui investit du temps, de l’énergie et des moyens financiers dans sa présence numérique souhaite naturellement savoir si ces efforts produisent des résultats. Le besoin de mesurer est donc parfaitement légitime.
En revanche, la manière dont ces mesures sont parfois présentées mérite d’être examinée avec davantage de recul.
Tout au long de cet article, nous avons tenté de montrer qu’il existait une différence fondamentale entre plusieurs niveaux de connaissance.
Une observation décrit un fait.
Une expérimentation permet d’étudier le comportement d’un système.
Une estimation cherche à représenter une réalité que l’on ne peut pas observer directement.
Une extrapolation tente enfin d’imaginer un phénomène plus vaste à partir d’informations limitées.
Ces quatre approches sont utiles.
Aucune ne mérite d’être rejetée.
Mais aucune ne devrait être interprétée comme si elle appartenait à la même catégorie que les autres.
Cette hiérarchie est probablement appelée à devenir l’un des grands enjeux des prochaines années.
Car, au fond, le débat ne concerne pas uniquement les intelligences artificielles.
Il concerne notre rapport à la donnée.
L’IA change peut-être moins la recherche… qu’elle ne change notre rapport à la mesure
Depuis l’apparition des moteurs de recherche, les professionnels du numérique ont progressivement pris l’habitude de travailler avec des données de plus en plus abondantes. Les plateformes publicitaires, les outils d’analyse d’audience, les CRM et les solutions marketing produisent aujourd’hui des milliers d’indicateurs différents.
Face à cette abondance, un réflexe s’est progressivement installé.
Lorsqu’un chiffre est disponible, nous avons naturellement tendance à penser qu’il représente une réalité objective.
Pourtant, l’intelligence artificielle nous rappelle brutalement qu’un indicateur n’est jamais indépendant de la méthode qui l’a produit.
Les IA génératives ne sont finalement qu’un révélateur.
Elles mettent en évidence une question que le marketing numérique avait parfois tendance à oublier :
Que savons-nous réellement ?
Cette interrogation est beaucoup plus importante qu’il n’y paraît.
Elle invite les entreprises à ne plus considérer un tableau de bord comme une vérité absolue, mais comme une représentation plus ou moins fidèle d’une réalité souvent beaucoup plus complexe.
Autrement dit, les décisions stratégiques ne devraient plus uniquement reposer sur la quantité de données disponibles.
Elles devraient également prendre en compte leur niveau de confiance.
Une philosophie plus qu’une technologie
Chez ONI, cette réflexion dépasse largement le sujet des intelligences artificielles.
Elle influence notre manière de concevoir les outils, d’analyser les performances d’un site Internet et d’accompagner les entreprises dans leurs décisions.
Depuis plusieurs années, nous avons progressivement fait évoluer nos méthodes de travail autour d’un principe simple.
Lorsqu’une donnée peut être observée directement, nous préférons toujours cette observation à une estimation.
Ce principe explique pourquoi nous accordons autant d’importance aux données de première main, aux journaux de serveurs, aux informations collectées directement sur les infrastructures que nous administrons et, plus généralement, à tout ce qui relève d’un phénomène effectivement observé.
Cela ne signifie pas que les estimations soient inutiles.
Bien au contraire.
Une estimation rigoureuse permet souvent d’éclairer une décision lorsque l’observation directe est impossible.
Les outils de GEO, les modèles statistiques et les expérimentations de type Query Fan-out continueront sans aucun doute à jouer un rôle important dans les années à venir.
Ils permettent d’explorer des territoires encore largement inconnus.
Ils ouvrent des pistes de réflexion.
Ils aident à comprendre les comportements des modèles.
Mais ils ne remplacent pas les données observées.
Ils les complètent.
Cette distinction nous paraît essentielle.
Les entreprises devront apprendre à hiérarchiser leurs indicateurs
Nous sommes probablement au début d’une nouvelle période de transition comparable à celle qu’a connue le référencement naturel il y a une vingtaine d’années.
À cette époque déjà, de nombreux outils prétendaient mesurer avec précision des phénomènes que Google lui-même ne dévoilait pas complètement. Avec le temps, les professionnels ont appris à distinguer les observations des estimations, à croiser plusieurs sources d’information et à interpréter les indicateurs avec davantage de recul.
L’intelligence artificielle nous oblige aujourd’hui à effectuer un apprentissage comparable.
Les entreprises qui tireront le meilleur parti de ces nouveaux outils ne seront probablement pas celles qui accumuleront le plus grand nombre de tableaux de bord.
Ce seront celles qui sauront répondre à une question beaucoup plus simple :
D’où provient cette donnée ?
Cette question devrait devenir un réflexe.
Provient-elle d’un événement réellement observé ?
D’une expérimentation ?
D’une modélisation statistique ?
Ou d’une extrapolation construite à partir d’hypothèses ?
La réponse conditionne directement le niveau de confiance qu’il est raisonnable d’accorder au résultat.

Une grille de lecture pour les années à venir
Au terme de cette réflexion, nous proposons une manière simple d’aborder les nouveaux indicateurs liés aux intelligences artificielles.
Avant d’interpréter un chiffre, posez-vous toujours quatre questions :
- Cette donnée a-t-elle été observée ou calculée ?
- Si elle est calculée, quelles hypothèses ont permis de la produire ?
- Pourrait-on reproduire cette mesure demain dans les mêmes conditions ?
- Quelle décision suis-je prêt à prendre sur la base de cette information ?
Ces quatre questions ne concernent pas uniquement le GEO.
Elles s’appliquent à l’ensemble des données utilisées par une entreprise.
Car une donnée n’a de valeur que si l’on comprend ce qu’elle représente réellement.
Mesurer moins… mais mesurer mieux
Le développement des intelligences artificielles génératives marque sans doute le début d’une nouvelle ère pour la recherche d’information.
Les méthodes d’optimisation continueront d’évoluer.
De nouveaux indicateurs apparaîtront.
De nouveaux outils promettront des analyses toujours plus fines.
Cette évolution est naturelle. Mais elle ne doit pas nous faire oublier un principe beaucoup plus ancien.
En science comme en entreprise, une décision ne vaut jamais mieux que la qualité des observations sur lesquelles elle repose.
Les entreprises qui réussiront demain ne seront peut-être pas celles qui utiliseront le plus d’intelligence artificielle.
Elles seront probablement celles qui auront appris à distinguer une observation d’une estimation, une estimation d’une extrapolation… et qui sauront construire leurs décisions sur les données dont elles comprennent réellement l’origine, les limites et le niveau de confiance.
Chez ONI, nous pensons que c’est précisément cette exigence qui permettra aux entreprises de transformer les données en décisions, et les décisions en résultats durables.

Deming rappelait que « sans données, chacun n’a que son opinion ». Nous ajouterions volontiers : sans comprendre l’origine de ces données, une opinion peut simplement sembler plus scientifique qu’elle ne l’est réellement.
Les entreprises qui réussiront demain ne seront probablement pas celles qui disposeront du plus grand nombre de données, mais celles qui sauront reconnaître les quelques données auxquelles elles peuvent réellement faire confiance.
FAQ – Mesurer sa visibilité sur les intelligences artificielles : les questions essentielles
Peut-on réellement mesurer sa visibilité sur ChatGPT ?
Oui, mais pas avec la même précision que l’on mesure son référencement naturel sur Google. Contrairement à un moteur de recherche traditionnel, ChatGPT ne publie pas les données relatives aux recommandations qu’il formule. Les méthodes actuelles permettent donc d’observer certains comportements ou de construire des estimations, mais elles ne donnent pas accès à une mesure exhaustive de la visibilité réelle d’une entreprise.
Pourquoi les outils GEO affichent-ils tous des résultats différents ?
Parce qu’ils ne disposent pas des mêmes sources de données ni des mêmes modèles statistiques. Certains s’appuient principalement sur des campagnes de Query Fan-out, d’autres utilisent des panels de navigation (clickstream), des données propriétaires ou encore des modèles de pondération différents. Deux outils peuvent donc analyser le même phénomène tout en produisant des indicateurs sensiblement différents.
Le Query Fan-out est-il une méthode fiable ?
Le Query Fan-out constitue une méthode expérimentale pertinente pour observer le comportement d’un modèle de langage dans un protocole donné. En revanche, il ne mesure pas directement la visibilité réelle d’une entreprise auprès des utilisateurs. Il fournit des observations statistiques dont l’interprétation doit tenir compte de l’évolution permanente des modèles d’IA.
Pourquoi un même test peut-il produire des résultats différents quelques jours plus tard ?
Les modèles de langage évoluent continuellement. Une mise à jour du modèle, une modification du system prompt, l’évolution des sources consultées ou des mécanismes de recherche peuvent modifier les réponses produites sans que l’utilisateur en soit informé. Les variations observées ne reflètent donc pas nécessairement une évolution de votre visibilité.
Les scores de visibilité IA sont-ils inutiles ?
Non. Ils constituent des indicateurs intéressants pour suivre des tendances ou comparer plusieurs stratégies. En revanche, ils ne doivent pas être interprétés comme des mesures absolues. Leur valeur dépend directement de la qualité des hypothèses utilisées pour construire le modèle qui les produit.
Pourquoi distinguer observation, expérimentation, estimation et extrapolation ?
Parce que ces quatre niveaux de données n’offrent pas le même degré de confiance. Une observation correspond à un événement réellement constaté. Une expérimentation étudie le comportement d’un système dans un protocole précis. Une estimation cherche à représenter une réalité difficilement observable. Enfin, une extrapolation projette cette réalité au-delà des données disponibles. Confondre ces niveaux conduit souvent à surestimer la précision de certains indicateurs.
Les journaux de serveur permettent-ils de tout mesurer ?
Non. Certaines applications mobiles ne transmettent pas toujours l’origine des visites, certains robots modifient leurs identifiants (User-Agent) et certaines plateformes renforcent régulièrement leurs politiques de confidentialité. Malgré ces limites, les journaux de serveur constituent aujourd’hui la source de données la plus proche de la réalité observable pour mesurer le trafic réellement généré par les intelligences artificielles.
Quelle différence entre la visibilité IA et le trafic IA ?
La visibilité IA désigne la probabilité qu’une intelligence artificielle cite votre entreprise dans une réponse. Le trafic IA correspond aux visiteurs qui arrivent effectivement sur votre site après avoir consulté cette réponse. Une entreprise peut bénéficier d’une forte visibilité sans générer beaucoup de trafic, ou inversement.
Pourquoi les intelligences artificielles sont-elles plus difficiles à mesurer que Google ?
Google renvoie principalement vers un index documentaire relativement stable. Les modèles de langage, eux, génèrent leurs réponses de manière probabiliste et évoluent en permanence. Ils ne constituent donc pas des instruments de mesure stables, ce qui rend les comparaisons dans le temps beaucoup plus délicates.
Les outils comme Semrush ou Ahrefs sont-ils fiables ?
Ces plateformes fournissent des estimations construites à partir des meilleures informations dont elles disposent. Leur objectif n’est pas de compter directement les recommandations formulées par les IA, mais d’en proposer une représentation statistique. Elles constituent donc d’excellents outils d’analyse, à condition de comprendre qu’elles modélisent une réalité qu’elles ne peuvent pas observer directement.
Pourquoi ONI privilégie-t-il les données de première main ?
Parce qu’une donnée observée directement possède généralement un niveau de confiance supérieur à une estimation. Lorsqu’une entreprise peut mesurer un phénomène sur sa propre infrastructure, par exemple grâce aux journaux de son serveur, il est logique de partir de cette observation avant d’interpréter des modèles statistiques plus éloignés de la réalité.
Le développement des IA va-t-il rendre le SEO obsolète ?
Non. Les intelligences artificielles modifient les modes d’accès à l’information, mais elles continuent largement à s’appuyer sur les contenus publiés sur le Web. Le référencement naturel évolue vers de nouvelles formes d’optimisation, sans pour autant disparaître. Les entreprises devront apprendre à piloter simultanément leur visibilité dans les moteurs de recherche et dans les réponses générées par les IA.
Quelle est aujourd’hui la méthode la plus fiable pour mesurer l’impact des IA sur un site web ?
Aucune méthode ne permet encore de mesurer parfaitement la visibilité d’une entreprise dans les réponses générées par les intelligences artificielles. En revanche, la combinaison de plusieurs approches offre une vision beaucoup plus pertinente : observations issues des journaux de serveur, analyse du trafic réellement reçu, expérimentations de type Query Fan-out et comparaison avec les données fournies par les outils spécialisés. C’est le croisement de ces sources qui permet aujourd’hui de construire l’analyse la plus fiable.
Pourquoi cet article parle-t-il davantage de métrologie que d’intelligence artificielle ?
Parce que le véritable sujet n’est pas uniquement l’IA. Il est celui de la qualité des données sur lesquelles reposent les décisions des entreprises. Les intelligences artificielles constituent simplement un excellent révélateur d’un problème beaucoup plus ancien : avant de faire confiance à un indicateur, il faut toujours comprendre comment il a été produit.
Faut-il chercher à tout mesurer ?
Probablement pas. L’histoire du marketing digital montre que la multiplication des indicateurs ne conduit pas nécessairement à de meilleures décisions. À vouloir tout quantifier, on risque parfois de perdre de vue l’essentiel : développer son activité. Les outils de mesure doivent rester des instruments d’aide à la décision, pas devenir une fin en soi. Une entreprise performante n’est pas celle qui possède le plus de tableaux de bord ; c’est celle qui sait distinguer les données réellement utiles de celles qui donnent simplement une illusion de précision.